
取得拡張生成 (RAG) は、独自のデータに基づいた正確で信頼性の高い回答を生成する、AIシステムを構築する技術です。
Microsoft FoundryでRAGを使ったAIチャットアプリを作成してみます。
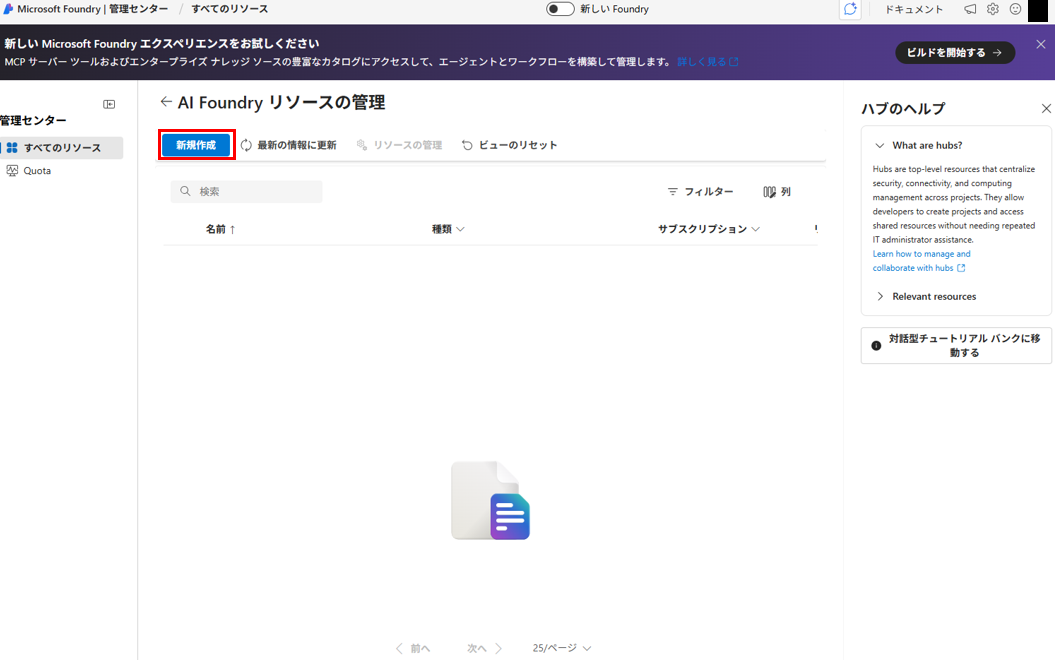
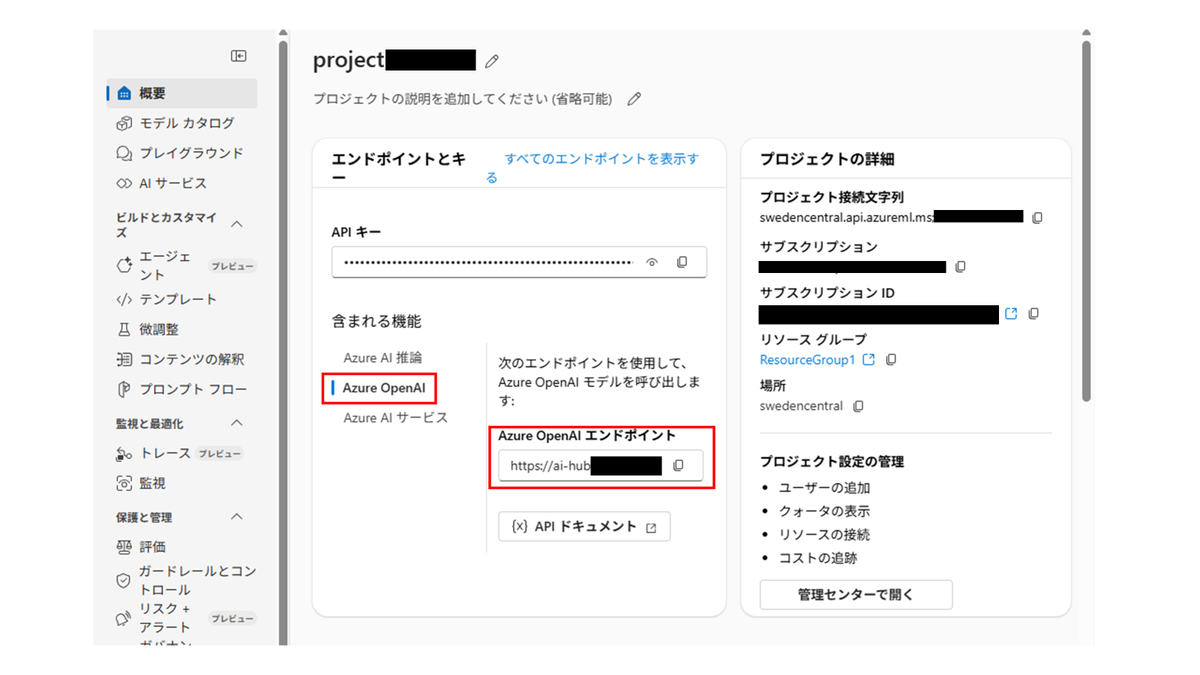
ハブとプロジェクトを作成する
Microsoft Foundry管理センターから新規作成します。
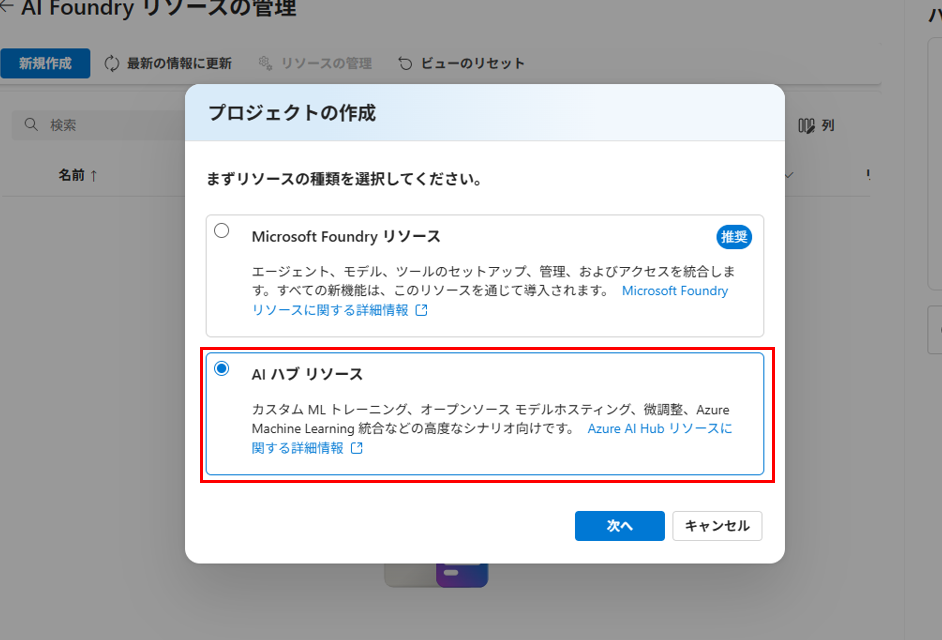
AIハブリソースを選択し、プロジェクトを作成します。
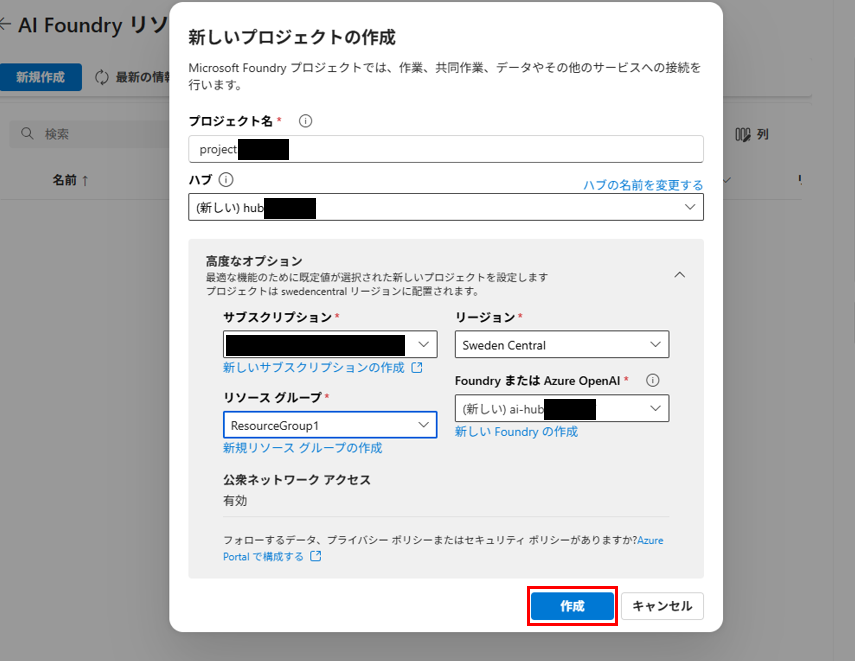
プロジェクトが完成します。
今回は割愛しますが、アプリを実装する際はAzure OpneAIのエンドポイントを利用します。
モデルをデプロイする
今回は2つのモデルをデプロイします。
text-embedding-ada-002
インデックス作成と処理のためにテキストデータをベクトル化する埋め込みモデル。
gpt-4o
データに基づいて質問に対する応答を生成できるモデル。
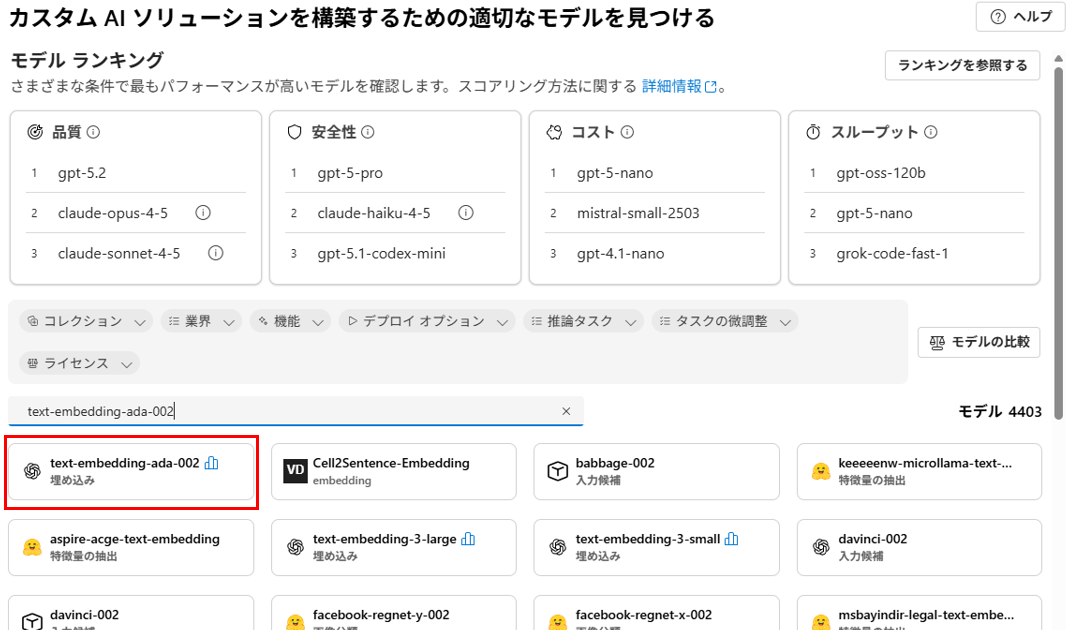
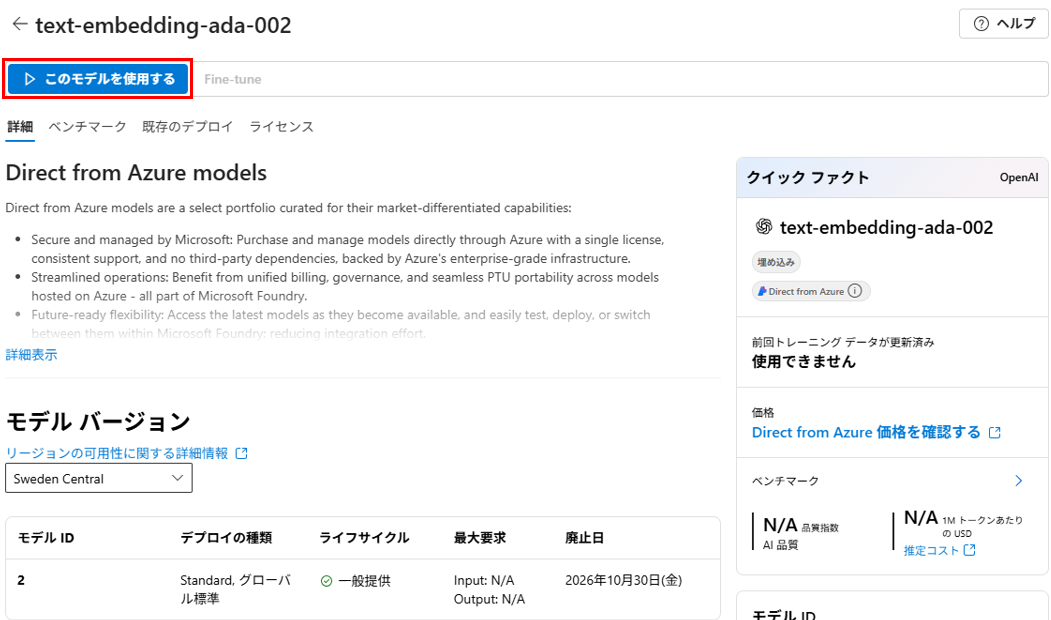
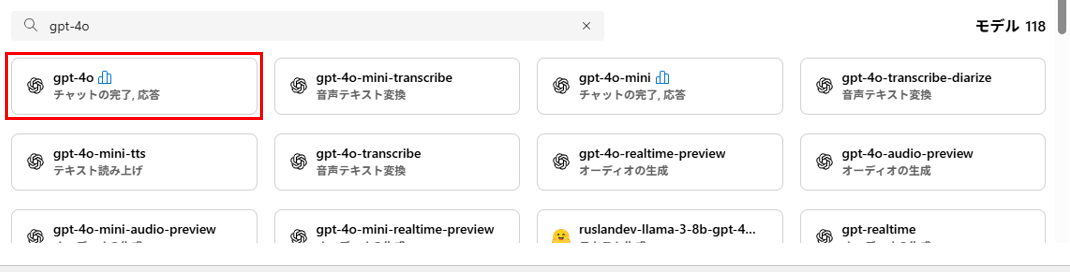
まずは、text-embedding-ada-002 を検索し、「このモデルを使用する」をクリックします。
「Azureモデルから直接」を選択し、デプロイします
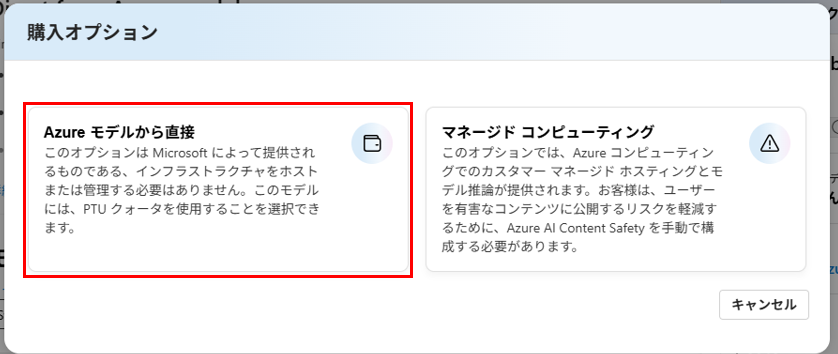
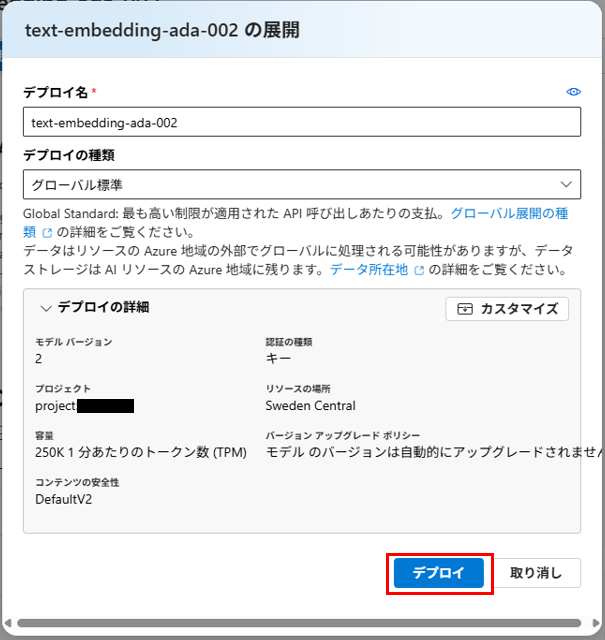
gpt-4o も同様にデプロイします。
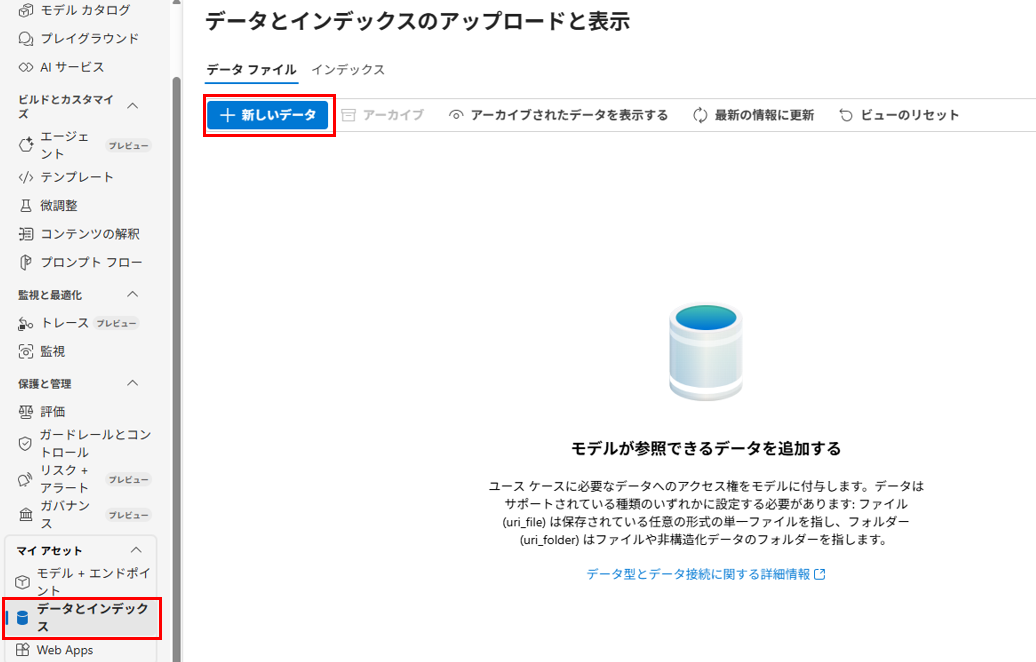
プロジェクトにデータを追加
RAGに使うデータをプロジェクトに追加します。
マイアセットの「データとインデックス」から「新しいデータ」をクリックします。
データソースとして、ファイルをアップロードします。
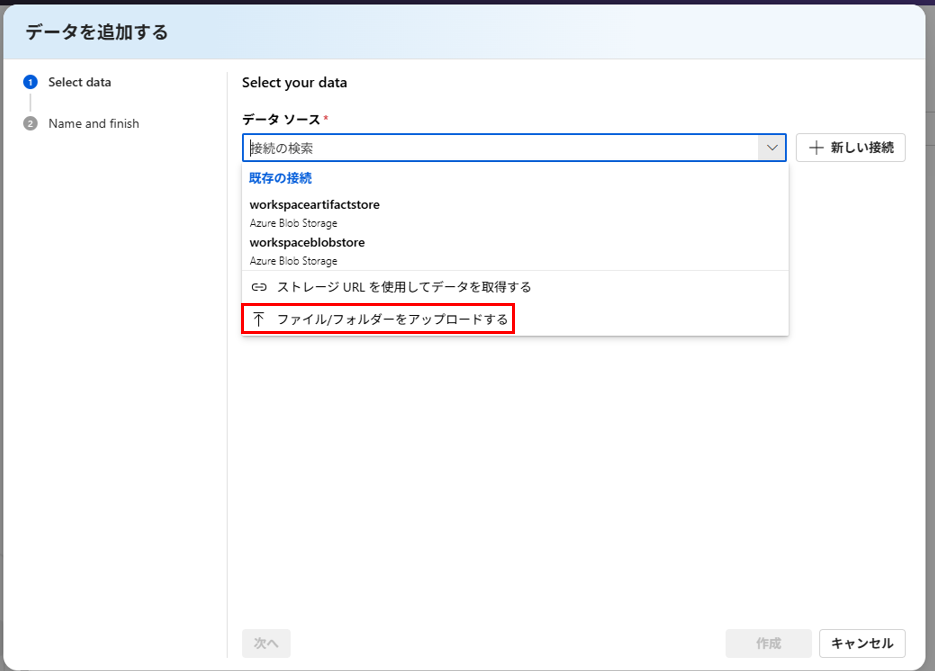
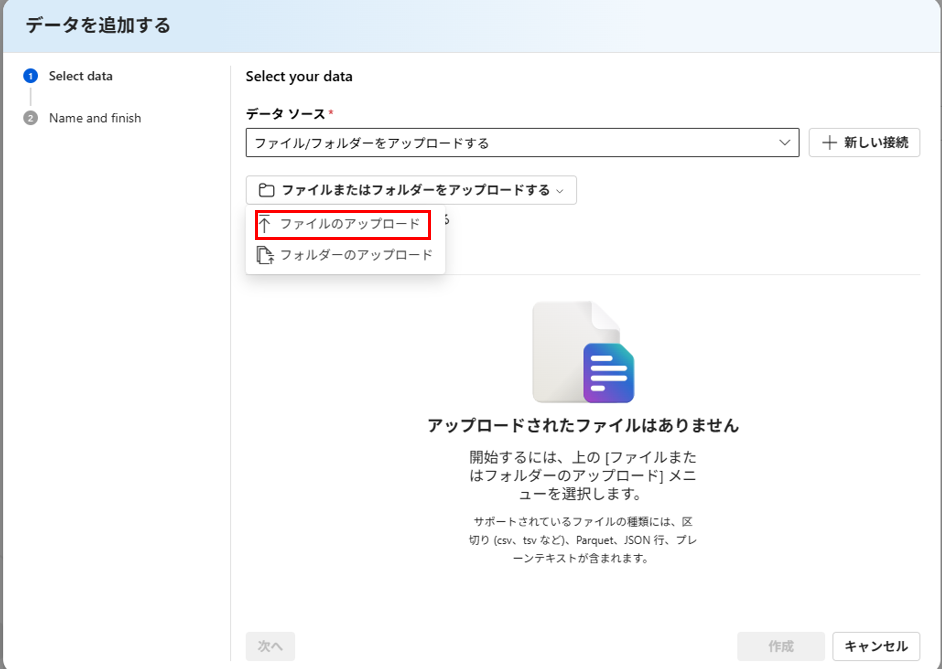
今回は、Azure Virtual MachinesのドキュメントをPDFファイルにしたものを利用します。

アップロードが完了しました。
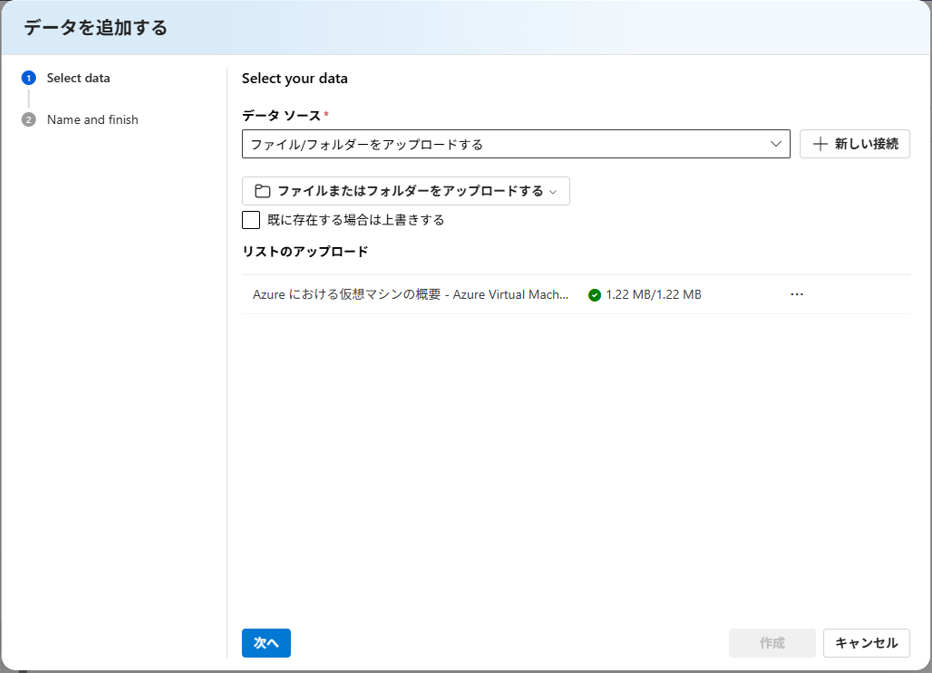
データ名は documents として作成します。
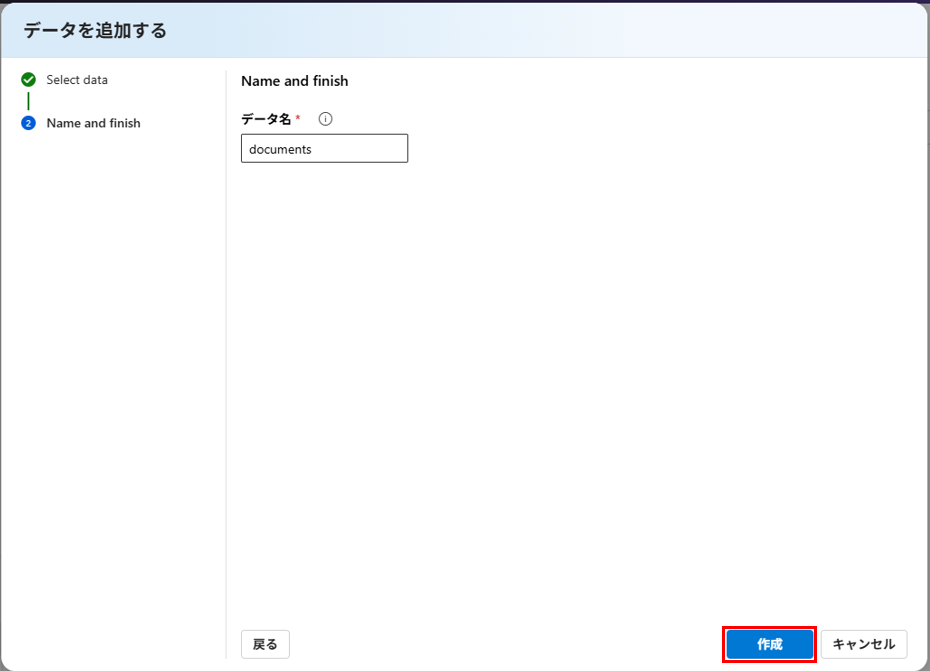
データが作成されました。
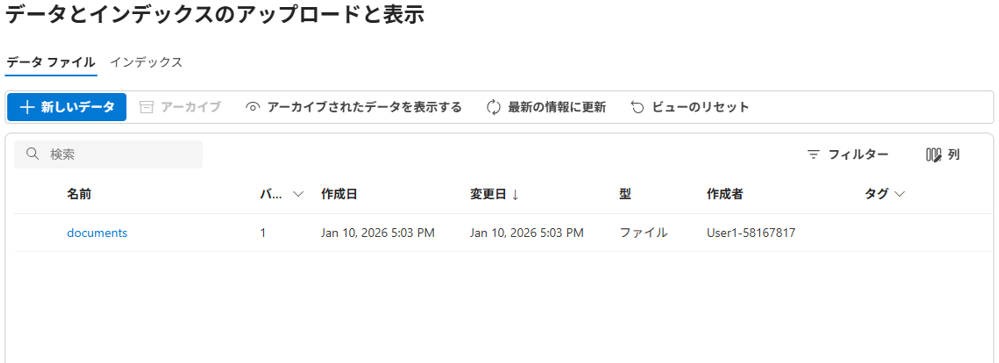
データのインデックスを作成
続いてインデックスを作成します。
マイアセットの「データとインデックス」から「新しいインデックス」をクリックします。
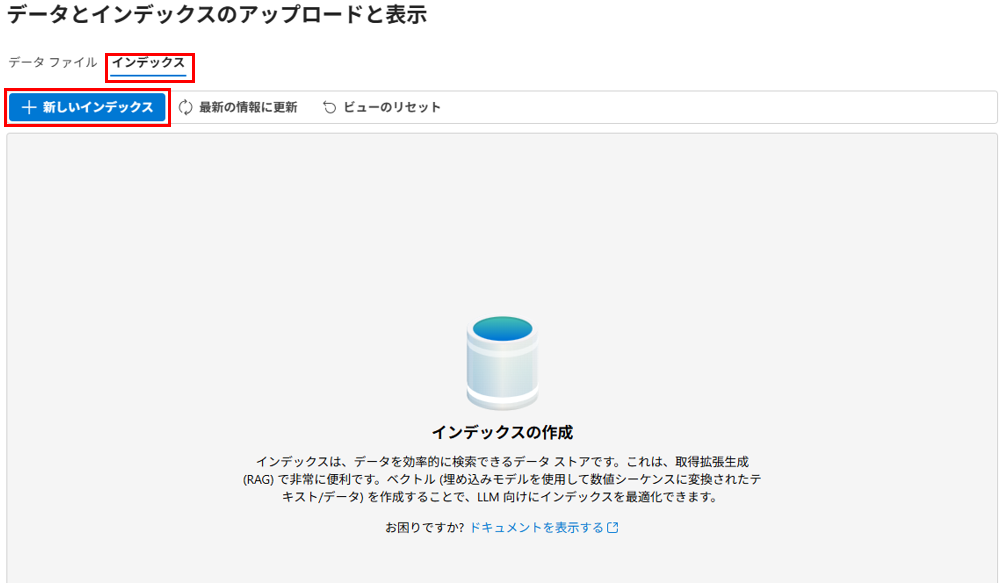
データソースに「Azure AI Foundryのデータ」を選択します。
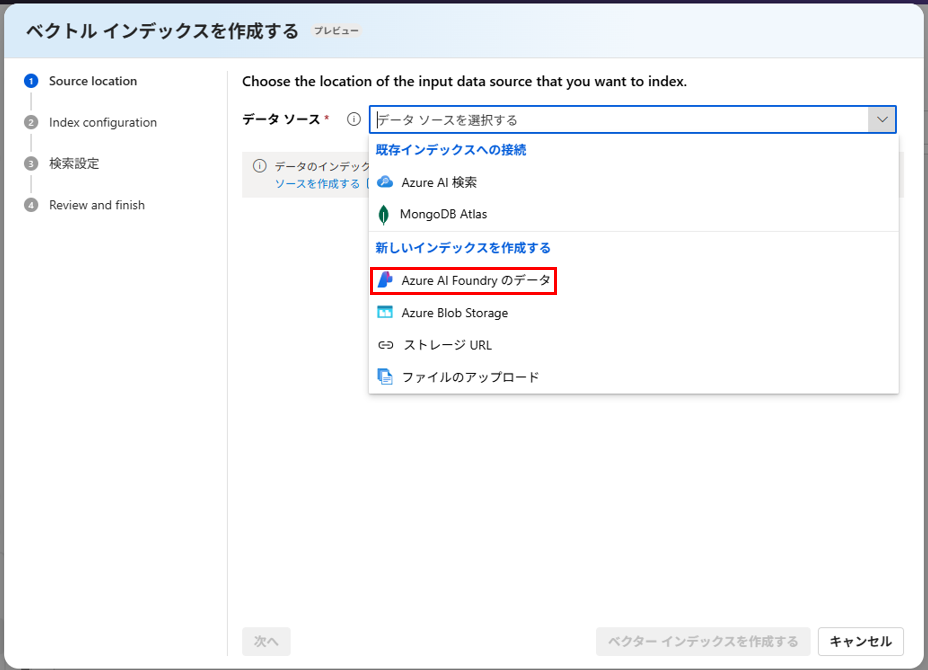
先ほど作成したデータ「documents」が表示されるので、選択します。
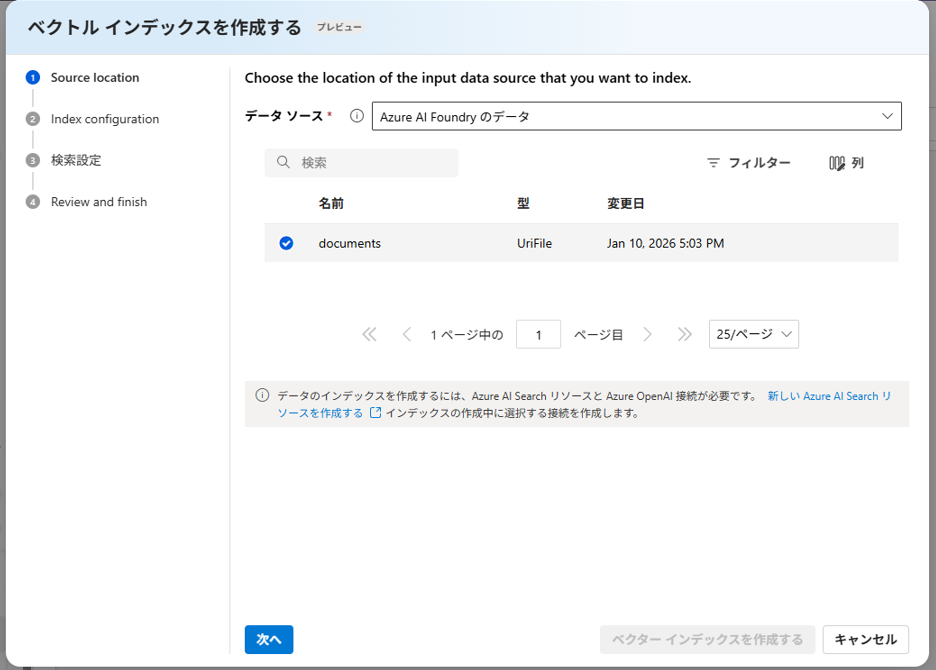
新しい Azure AI Search リソースを作成します。
Azureの画面に遷移するので、検索サービスを作成します。
検索サービスの作成が完了しました。
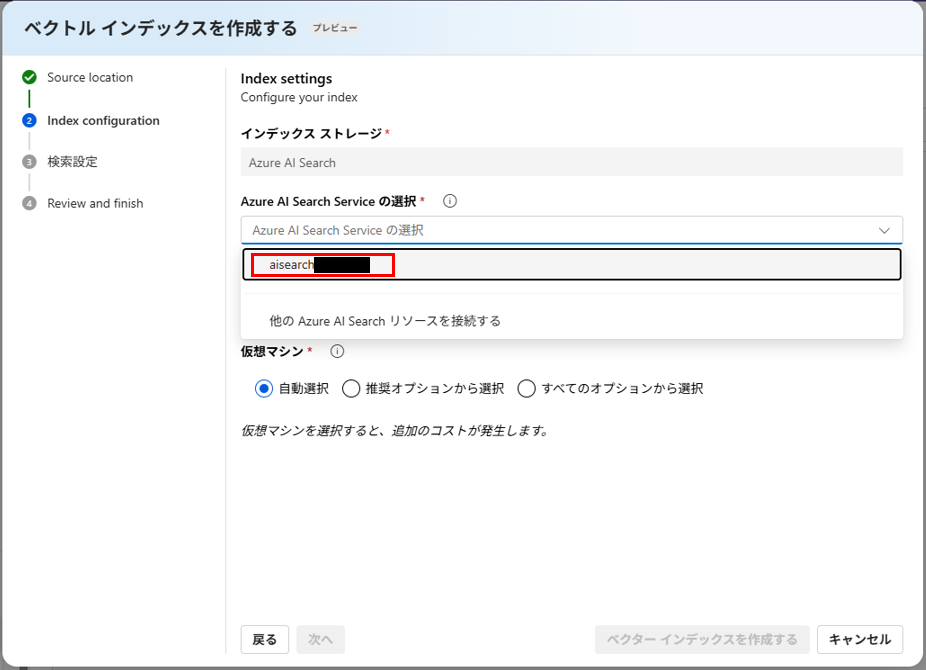
インデックス作成画面に戻り、他の Azure AI Search リソースを接続します。
先ほどの AI Search リソースが表示されるので、接続を追加します。
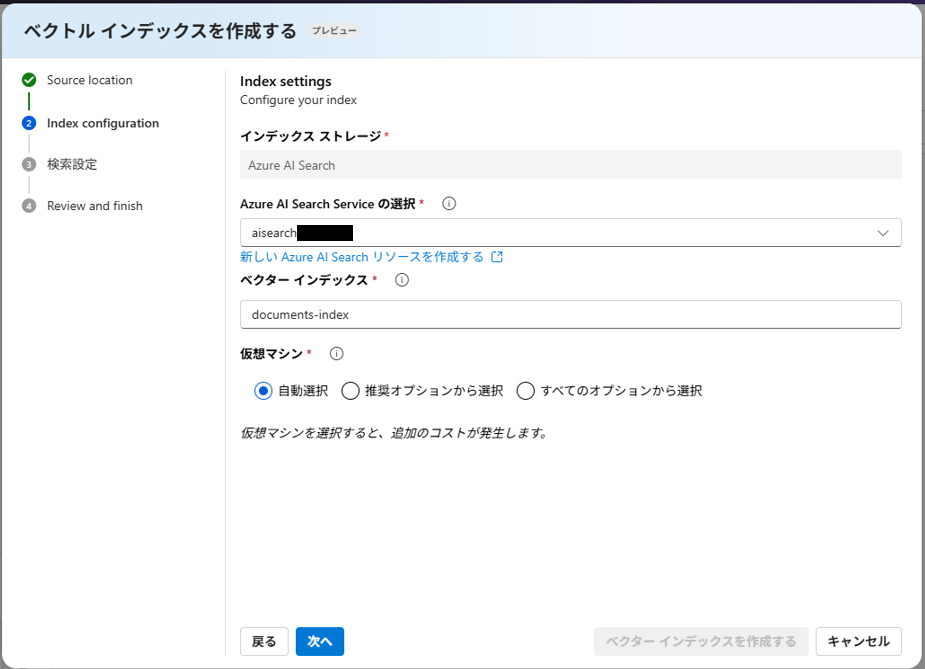
これで選択できるようになるので、選択します。
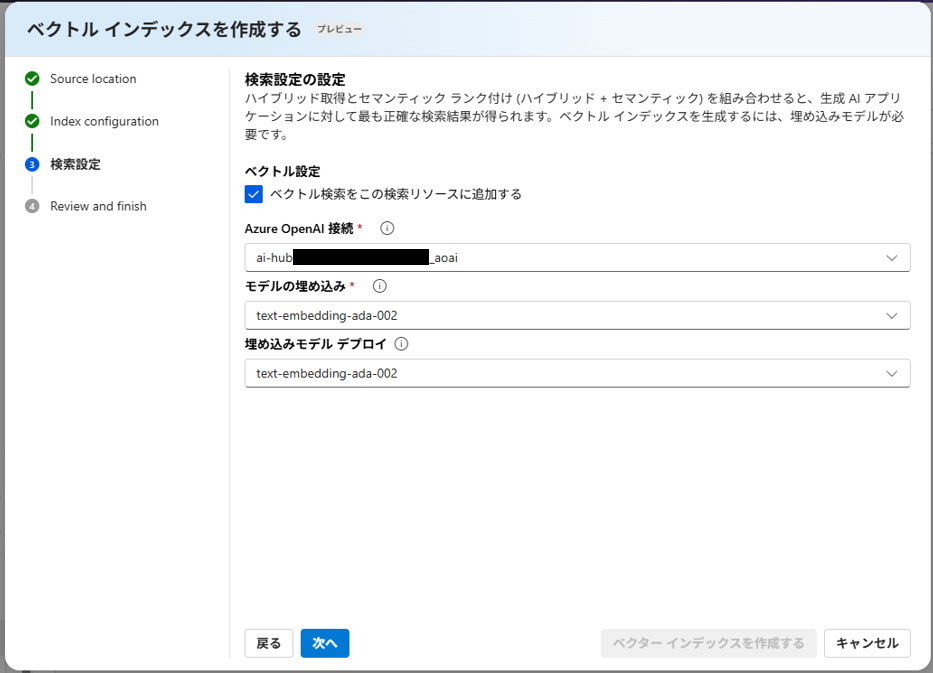
検索設定で、「ベクトル検索をこの検索リソースに追加する」にチェックを入れます。
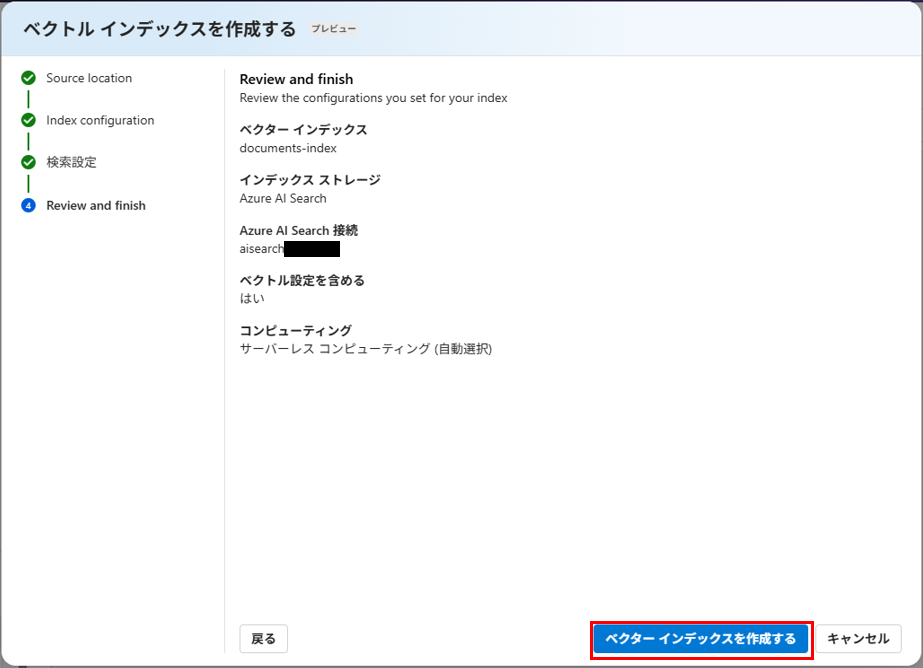
設定内容を確認し、インデックスを作成します。
状態がRunningなので少し待ちます。
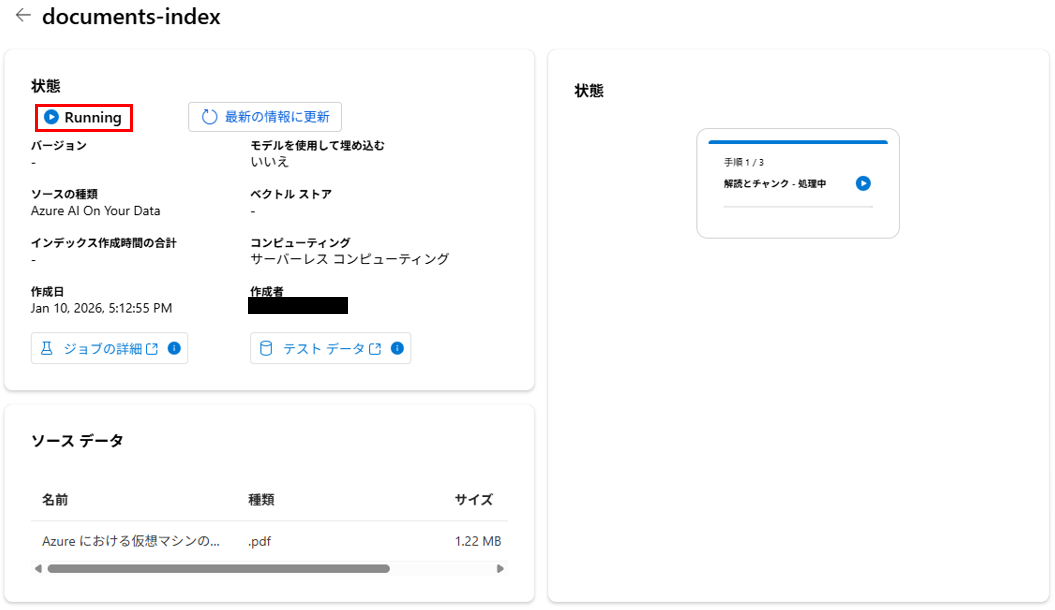
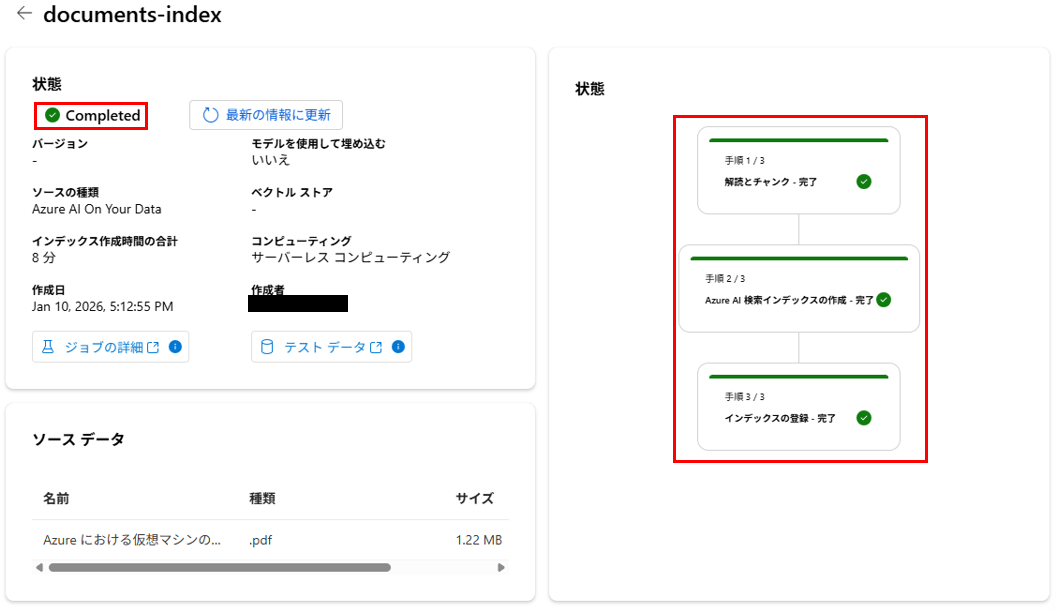
状態がCompletedになるとインデックス作成が完了します。
ちなみに裏では、①チャンクと埋め込み、②インデックスの作成、③インデックスの登録 が行われています。
プレイグラウンドでインデックスを確認する
プレイグラウンドから「チャットプレイグラウンドを試す」をクリックします。
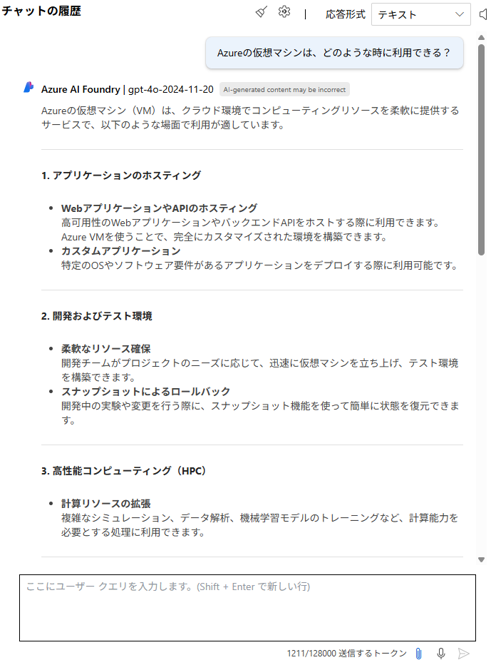
まずは、仮想マシンのユースケースについて聞いてみます。
様々なユースケースについて回答をしてくれます。
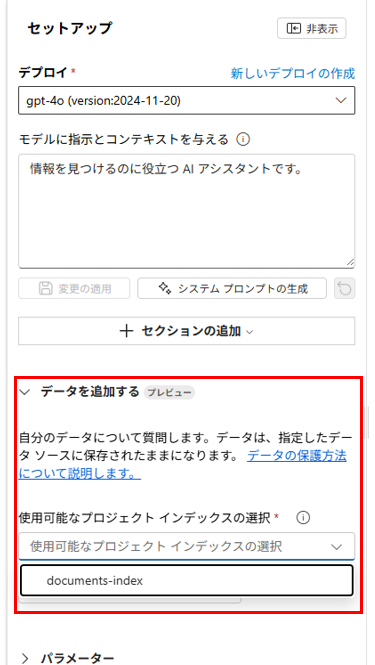
次に、データを追加するから先ほど作成したインデックスを選択します。
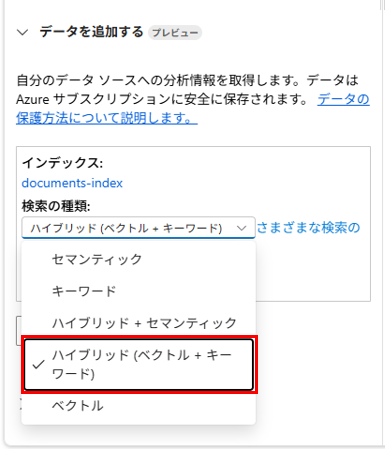
検索の種類として、「ハイブリッド (ベクトル + キーワード)」を選択します。
先ほどと同様に、仮想マシンのユースケースについて聞いてみます。
今度はデータソースに基づいた回答をしてくれます。
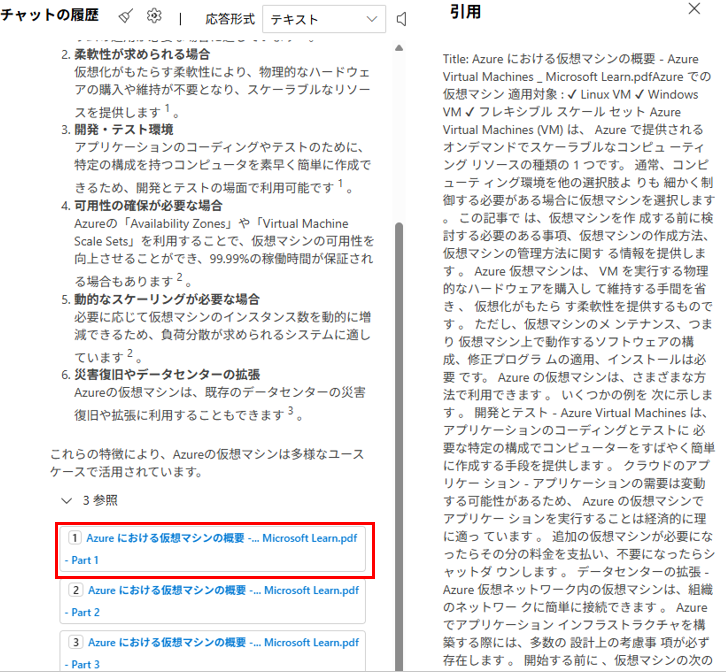
各回答にどのデータを参照したのかも表示されます。
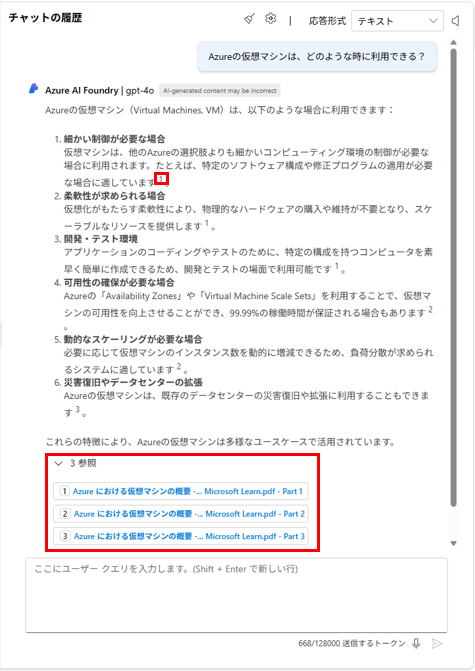
参照の詳細を確認することもできます。
まとめ
Microsoft Foundry を活用することで、RAGを使ったAIチャットアプリを簡単に構築できることを確認できました。
今回のシンプルなサンプルを足掛かりに、データの追加、インデックス設計の最適化、メタデータ検索の強化、エージェント機能との統合など、さらに高度なRAGアプリケーションにも発展させていけると思います。